




集積回路 IC チップ 1 スポット購入 EPM240T100C5N IC CPLD 192MC 4.7NS 100TQFP


製品の属性
| タイプ | 説明 |
| カテゴリー | 集積回路 (IC) 埋め込み CPLD (複雑なプログラマブル ロジック デバイス) |
| 製造元 | インテル |
| シリーズ | MAX® II |
| パッケージ | トレイ |
| 標準パッケージ | 90 |
| 製品の状態 | アクティブ |
| プログラマブルタイプ | システムプログラマブルで |
| 遅延時間 tpd(1) Max | 4.7ns |
| 電圧供給 – 内部 | 2.5V、3.3V |
| ロジックエレメント/ブロック数 | 240 |
| マクロセルの数 | 192 |
| I/O数 | 80 |
| 動作温度 | 0℃~85℃(TJ) |
| 取付タイプ | 表面実装 |
| パッケージ・ケース | 100-TQFP |
| サプライヤーデバイスパッケージ | 100-TQFP (14×14) |
| 基本製品番号 | EPM240 |
コストは 3D パッケージ チップが直面する主要な問題の 1 つであり、インテルが最先端のパッケージング技術を活用してチップを大量生産するのは Foveros が初めてとなります。しかしインテルは、3D Foveros パッケージで製造されたチップは標準のチップ設計と比べて非常に価格競争力があり、場合によってはさらに安くなる可能性があると述べています。
Intel は、Foveros チップを可能な限り低コストでありながら、同社が定めたパフォーマンス目標を満たせるように設計しました。これは、Meteor Lake パッケージの中で最も安価なチップです。Intel は Foveros インターコネクト/ベース タイルの速度をまだ共有していませんが、コンポーネントはパッシブ構成で数 GHz で実行できると述べています (この声明は、Intel がすでに開発している中間層のアクティブ バージョンの存在を示唆しています) )。したがって、Foveros では、設計者が帯域幅や遅延の制約について妥協する必要はありません。
インテルはまた、この設計がパフォーマンスとコストの両方の点で十分に拡張できることを期待しています。これは、他の市場セグメント向けに特化した設計や、高性能バージョンのバリエーションを提供できることを意味します。
シリコンチップのプロセスが限界に近づくにつれて、トランジスタあたりの高度なノードのコストは指数関数的に増加しています。また、小規模なノード向けに新しい IP モジュール (I/O インターフェイスなど) を設計しても、投資収益率はあまり高くありません。したがって、「十分な」既存ノードで重要ではないタイル/チップレットを再利用すると、テスト プロセスを簡素化することはもちろん、時間、コスト、開発リソースを節約できます。
単一チップの場合、インテルはメモリや PCIe インターフェイスなどのさまざまなチップ要素を連続してテストする必要があり、これは時間のかかるプロセスになる可能性があります。対照的に、チップメーカーは時間を節約するために小型チップを同時にテストすることもできます。カバーには、設計者が設計ニーズに合わせてさまざまな小型チップをカスタマイズできるため、特定の TDP 範囲に合わせてチップを設計する際にも利点があります。
これらのポイントのほとんどは聞き覚えのあるもので、2017 年に AMD をチップセットの道に導いた要因と同じです。AMD はチップセットベースの設計を採用した最初の企業ではありませんでしたが、この設計哲学を使用して、最新のチップを大量生産することは、インテルが少し遅れて実現したようだ。ただし、Intel が提案する 3D パッケージング テクノロジは、AMD の有機中間層ベースの設計よりもはるかに複雑であり、利点と欠点の両方があります。
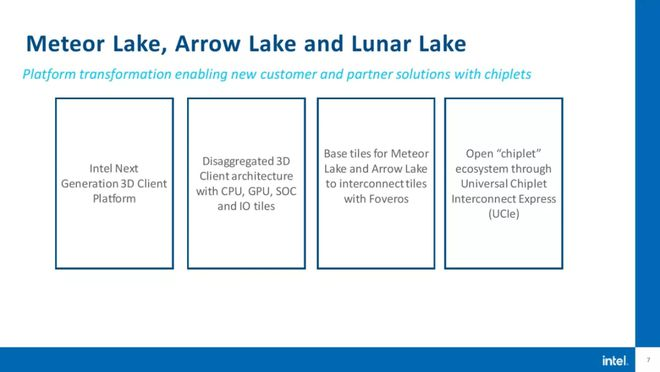
この違いは最終的には完成したチップに反映され、Intelは新しい3DスタックチップMeteor Lakeが2023年に発売され、Arrow LakeとLunar Lakeが2024年に発売される予定だと述べている。
Intelはまた、1000億個以上のトランジスタを搭載するPonte Vecchioスーパーコンピュータチップが世界最速のスーパーコンピュータ「Aurora」の中核となる見込みだと述べた。





